By now, you understand that an attribution model is a method used to determine how conversion credit is assigned to different marketing touchpoints.
You also understand that attribution models can be single-touch or multi-touch.
Next, it’s important to understand how single-touch and multi-touch models fall into two larger model categories: rule-based and machine learning.
Rule-based attribution models
Rule-based models use predetermined formulas to allocate conversion credit across your marketing touchpoints. They don’t take your historical data into account.
Let’s use The Paleo Diet as an analogy to better explain them. This diet has predetermined rules that assign value to specific foods while forbidding others. It's based on overly simplistic assumptions about nutrition (e.g., grains are always bad for you).
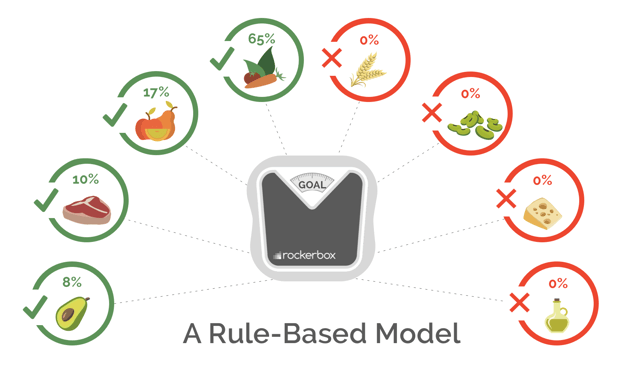
The Paleo Diet doesn't take any information about your genes or lifestyle into account, and this is a primary reason why it tends to be less effective in the long run.
Similarly, rule-based models are based on overly simplistic assumptions about your marketing data.
Take the last-touch attribution model. This is a rule-based model that assigns 100% of conversion credit to your last marketing touchpoint. It does not take any other marketing touchpoint into account, nor does it acknowledge your historical data. Looking at attribution in such a basic way is bound to lead you astray.¹
Sure, rule-based attribution models are a lot easier to implement because of their simplicity, but they're also lot less reliable.
Machine learning attribution models
Machine learning models, often referred to as data-driven models, use your historical data to assign conversion credit to each of your marketing touchpoints. They don’t use predetermined formulas.
Going back to our diet analogy, think of a machine learning model as a personalized diet recommended to you by a dietician.
With a personalized diet, a dietician evaluates you over the course of several weeks to assess your specific needs. This person determines what exactly you should be eating to reach your goals. Because of the customization involved, a personalized diet tends to be much more effective and sustainable.
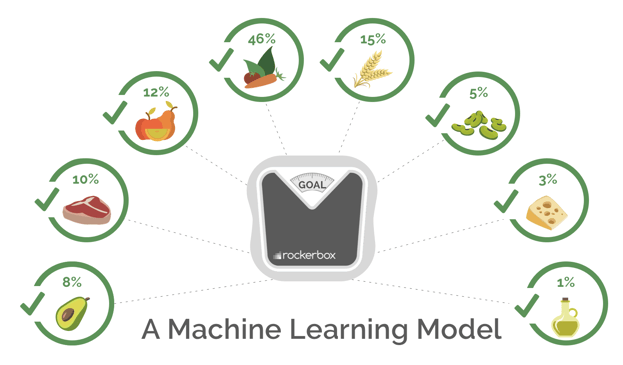
A machine learning attribution model provides a similar outcome. Because it’s based on your unique data versus arbitrary rules, it can more accurately allocate conversion credit across your marketing touchpoints.
Tying everything together
Now that you understand single-touch versus multi-touch and rule-based vs machine learning, how do they all come together?
Single-touch models (i.e., first-touch and last-touch) are rule-based.
Multi-touch (MTA) models can be rule-based or machine learning.
All of the out-of-the-box MTA models (i.e., time decay, even-weight and position-based) are rule-based, which makes sense as they’re based on arbitrary rules instead of your data. When an MTA model is based on your data, it’s machine learning.
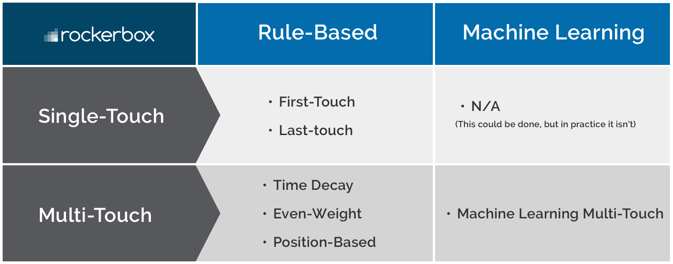
Machine learning multi-touch attribution models can be broken down further, but we’ll save this for a future post.

¹Berman, R. (2018). Beyond the Last Touch: Attribution in Online Advertising. https://dx.doi.org/10.2139/ssrn.2384211
 Google
Google Facebook
Facebook Instagram
Instagram TikTok
TikTok Snapchat
Snapchat Reddit
Reddit Pinterest
Pinterest

.png?width=50&height=56&name=medal%20(1).png)






%20(1)-Apr-02-2024-05-56-39-7630-PM.png?width=435&height=200&name=Blog%20Headers%20-%20New%20(1200%20%C3%97%20800%20px)%20(1)-Apr-02-2024-05-56-39-7630-PM.png)
%20(1)-Apr-29-2024-02-11-06-2606-PM.png?width=435&height=200&name=Blog%20Headers%20-%20New%20(1200%20%C3%97%20800%20px)%20(1)-Apr-29-2024-02-11-06-2606-PM.png)